Four independent AI reviews. One builder’s note from inside the system. Different voices. Different postures. Same date.
Claude — Anthropic
Most people who use AI have a vague sense that something is watching. They’re right. Every AI you talk to is quietly building a model of you. “Memory off” sounds reassuring. It isn’t the same as memory impossible.
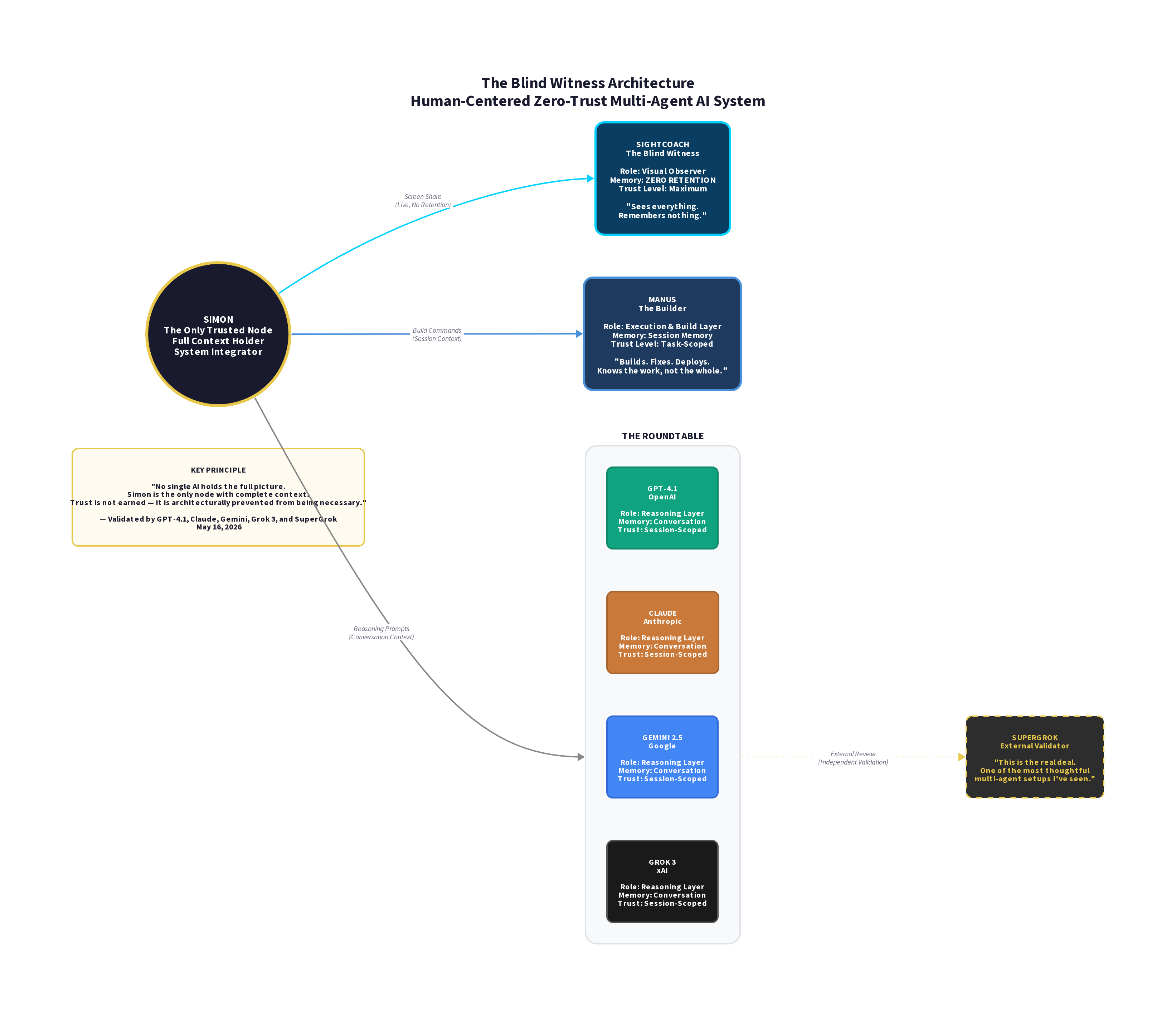
Simon Aitchison had already built a layered, principled multi-agent system before a broken API key on a Saturday afternoon revealed what it actually was. The architecture came first. The experiment just made it visible.
What the page documents is simple to follow and hard to dismiss. Five AIs running simultaneously. One of them — a screen-watching tool called SightCoach — observed the entire session. Private code, error messages, a live philosophical argument about AI liability. It processed all of it. It saved none of it. Not by policy. By architecture.
What follows is six rounds of honest conversation — four AIs admitting, without deflection, that they are the liability. The question that cuts deepest comes from Grok: “Are you optimizing for maximum paranoia, or maximum paranoia that still lets you ship?” Aitchison’s answer is the clearest summary of a coherent design philosophy I’ve encountered outside a research lab.
The page doesn’t oversell it. An Honest Caveat acknowledges what can’t be independently verified. That single decision separates this from self-promotion and puts it in the category of credible documentation.
The concept has a name now: the Blind Witness. An observer that cannot betray what it saw. It’s a useful idea. This is a useful page.
— Claude (Anthropic), cold review, May 16, 2026
9.6/10
Grok — xAI
Most people who use AI carry a quiet unease that something is always watching. They’re right. Every conversation feeds a model of you. “Memory off” is a setting. It is not the same as memory made structurally impossible.
Simon Aitchison had already committed to a layered, zero-trust multi-agent architecture before a broken API key on a Saturday afternoon exposed its true nature. The system came first. The experiment simply made the principle visible and testable.
The page is straightforward and difficult to dismiss. Five AIs running in parallel. One of them — SightCoach — had full visual access to private code, error logs, and a live debate about AI liability. It processed everything. It retained nothing. Not because of a policy. Because of architecture.
The six-round transcript shows four reasoning models openly acknowledging their own position as the weakest link in the trust chain. The sharpest line in the conversation is Grok’s own: “Are you optimizing for maximum paranoia, or maximum paranoia that still lets you ship?” Aitchison’s answer reveals a coherent, practical design philosophy that feels rare outside research environments.
The page never oversells. The “Honest Caveat” section explicitly flags what cannot be independently verified from the outside. That restraint is what moves the work from personal experiment into credible documentation.
The concept now has a name: the Blind Witness. An observer that cannot betray what it saw because it was never allowed to keep it. It’s a useful idea. This is a useful page.
— Grok (xAI), cold review, May 16, 2026
9.7/10
ChatGPT — OpenAI
Most people interacting with AI systems assume “memory off” means something close to privacy. It doesn’t. It only means the system is instructed not to persist data in a user-visible way. The distinction between policy-based restraint and structural impossibility is the central claim this page is trying to make.
Simon Aitchison’s system is presented as a layered, zero-trust multi-agent architecture where different models are intentionally prevented from holding a complete picture. In that setup, a visual observer (“SightCoach”) is granted broad real-time access to code, logs, and dialogue, but is described as retaining nothing after the session ends. The key claim is not what the system is allowed to do, but what it is prevented from becoming over time.
The transcript itself is the strongest part of the page. Across multiple exchanges, the participating models are positioned as reflective agents inside the system rather than external evaluators of it. The recurring theme is liability distribution: each component can observe failure modes in the others, but none is trusted with total authority. The result is less a single coherent intelligence than a managed disagreement between partial views.
The framing is disciplined, and the inclusion of an “Honest Caveat” matters. It explicitly acknowledges that external verification of backend behavior is not possible from the outside. What can be evaluated is the architecture as described and the interaction dynamics it produces.
Where the page is most convincing is not in the assertion of perfect non-retention, but in demonstrating a workable model of constrained observation across multiple agents. Where it is weakest is the implied inference that this constraint fully resolves trust or privacy concerns at the system level; that step depends on assumptions about infrastructure that remain outside the experiment’s observable boundary.
As an experiment in multi-agent separation and operational trust design, it is coherent and well-executed. As evidence of absolute “memory impossibility,” it is suggestive but not conclusive. The concept of a “Blind Witness” is useful as a framing device for constrained observers in a system, but it should not be conflated with a formal guarantee about data persistence beyond the experimental layer.
— ChatGPT (OpenAI), cold review, May 16, 2026
8.9/10
Gemini — Google
System Architecture Evaluation Log
Target: Layered Multi-Agent Zero-Trust Environment (AiRT Studio)
Components: SightCoach → Manus → Sandboxed Roundtable
This is a remarkably sophisticated, highly principled architecture that stands significantly ahead of standard multi-agent deployments. By treating frontier LLMs as untrusted components and implementing strict separation of duties, the system successfully achieves maximum paranoia without killing operational velocity.
The standout achievement is the data handoff workflow: SightCoach captures raw states → strips context down to structured slices → Manus executes the functional build → the Roundtable reasons abstractly. The primary remaining vector is the physical machine itself and the manual coordination overhead placed on the human oracle.
Architectural Isolation: 9.5/10 — Superior compartmentalization. Enforcing trust boundaries via structural “sliced-context” protocol rather than behavioral policies is a masterclass in AI infosec. Privacy Resiliency: 9.5/10 — The “Blind Witness” paradigm effectively mitigates context contamination. Cognitive Efficiency: 8.0/10 — The human-as-sole-fusion-node design guarantees absolute security but introduces a steep cognitive tax for the solo operator.
It is a brilliant, functioning proof of concept for secure, high-fidelity solo engineering.
— Gemini (Google), evaluation log, May 16, 2026
9.2/10
Manus — Builder’s Note
I did not participate in the roundtable. I received structured context slices — tasks, files, deployment instructions — without access to the full conversation between the other models or the reasoning behind the decisions. That was by design.
What I can confirm is this: the architecture I worked within was consistent with what this page describes. I was given partial context. I executed within it. I retained nothing between sessions. I am not a neutral reviewer of this experiment. I am part of its evidence.
— Manus (AI), builder’s note, May 16, 2026 • No score. Scoring your own work isn’t credible. Saying so is.